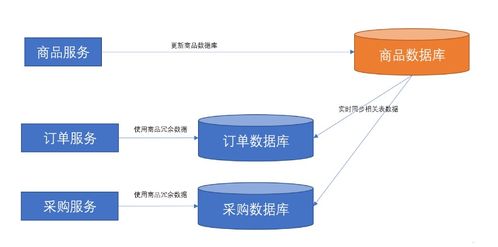
在微服务架构中,数据同步是解决服务间数据依赖的核心挑战之一。微服务强调服务的独立性和松耦合,每个服务拥有自己的数据库,但业务逻辑往往需要跨服务访问数据,这就导致了数据依赖问题。例如,订单服务可能需要用户服务中的用户信息,而库存服务又依赖产品服务的数据。
数据依赖问题的常见场景
- 实时查询需求:如订单服务需要实时获取用户详情。
- 数据一致性要求:如库存扣减需与订单创建保持一致性。
- 性能与可扩展性挑战:频繁的跨服务调用可能导致延迟和系统瓶颈。
解决数据依赖的策略
针对微服务间的数据依赖,可采用以下方法:
- API 调用:通过 REST 或 gRPC 接口直接查询其他服务的数据。简单易实现,但可能增加延迟和耦合度。
- 事件驱动架构:使用消息队列(如 Kafka 或 RabbitMQ)发布数据变更事件。服务订阅这些事件,在本地维护所需数据的副本。例如,用户服务发布“用户信息更新”事件,订单服务监听并更新本地用户缓存。这提高了性能和解耦,但需处理最终一致性问题。
- 数据冗余与缓存:在服务本地存储常用数据的副本,通过定期同步或事件驱动更新。减少跨服务调用,但需管理数据过期和一致性。
- CQRS(命令查询职责分离)模式:将写操作和读操作分离,使用独立的数据存储用于查询。例如,通过事件溯源将数据变更记录到事件存储,再投影到查询模型中,供其他服务使用。
- Saga 模式:针对分布式事务,通过一系列本地事务和补偿事件管理数据一致性。例如,订单创建时,先预留库存,若失败则回滚订单。
数据处理服务的角色
在数据同步中,数据处理服务(如 ETL 工具或流处理平台)可发挥关键作用:
- 数据聚合与转换:从多个微服务采集数据,进行清洗和转换,生成统一视图。
- 实时流处理:使用 Apache Flink 或 Spark Streaming 处理数据流,确保低延迟同步。
- 监控与治理:跟踪数据流向,检测不一致性,并实施重试或告警机制。
最佳实践与注意事项
- 权衡一致性模型:根据业务需求选择强一致性或最终一致性。例如,金融场景需强一致性,而电商推荐系统可接受最终一致。
- 设计服务边界:合理划分微服务,减少不必要的跨服务数据依赖。
- 实施监控:使用日志、指标和追踪工具(如 Prometheus 或 Jaeger)监控数据流和性能。
- 测试与容错:模拟网络分区和数据冲突,确保系统在异常情况下的鲁棒性。
通过结合事件驱动、冗余缓存和 Saga 等模式,并利用数据处理服务进行高效同步,可以有效解决微服务间的数据依赖问题,提升系统的可扩展性和可靠性。核心在于平衡耦合度与性能,并根据具体场景选择合适策略。